

A maioria das pessoas não sabe que o termo ‘Inteligência Artificial’ se refere a uma tecnologia que é desenvolvida para imitar o comportamento humano. Quanto mais se aproximar, sendo que a meta é que um humano não consiga diferenciar uma interação com uma IA de outra com um ser humano verdadeiro.
Entretanto, essa afirmação está cheia de nuances. Uma IA é simplesmente um algoritmo, muito complexo e específico, sim, mas nada mais. Esse algoritmo tem capacidades de reescrever partes de si mesmo, o que é chamado de ‘aprendizado’ ou ‘treinamento’, enquanto ingere e analisa enormes quantidades de dados. Uma IA nunca vai parar de aprender, durante a sua fase de desenvolvimento, cientistas e engenheiros inserem perguntas e esperam que ela ofereça respostas que precisam ser atender ao que foi perguntado e parecer uma resposta dada por um ser humano. No começo, essas respostas serão incompletas, erradas e estranhas, sendo recusadas e isso servirá como feedback para o algoritmo tentar outra coisa na próxima. Sim, muito parecido com tentativa e erro. O aprendizado da IA é acelerado porque os dados que ela ingere tem um poderoso contexto, por exemplo, se visitar um site como o StackOverflow, vai ler perguntas feitas por humanos, enriquecendo seu acervo linguístico e acessando as respostas corretas, inclusive com um sistema de pontuação que indica quais as melhores respostas entre as certas.
Entretanto, toda interação humana é subjetiva, o que quer dizer que perguntas e respostas estão permeadas por cultura, características pessoais, ou seja tem um viés que está presente tanto nos dados ingeridos como nas interações com os cientistas que participam do seu treinamento.
Em 2020, Colin Madland, um pesquisador da universidade canadense de Victória, estava tentando ajudar um colega que tinha problemas ao tentar usar fundos automáticos da plataforma de videoconferência Zoom. Ao ativar a funcionalidade, a cabeça era convertida em fundo.

O colega de Colin era negro.
Colin foi ao Twiter postar o problema e tentar obter ajuda com os seus contatos, muitos especialistas em tecnologia. Ele postou algumas imagens para exemplificar o problema e teve uma surpresa:
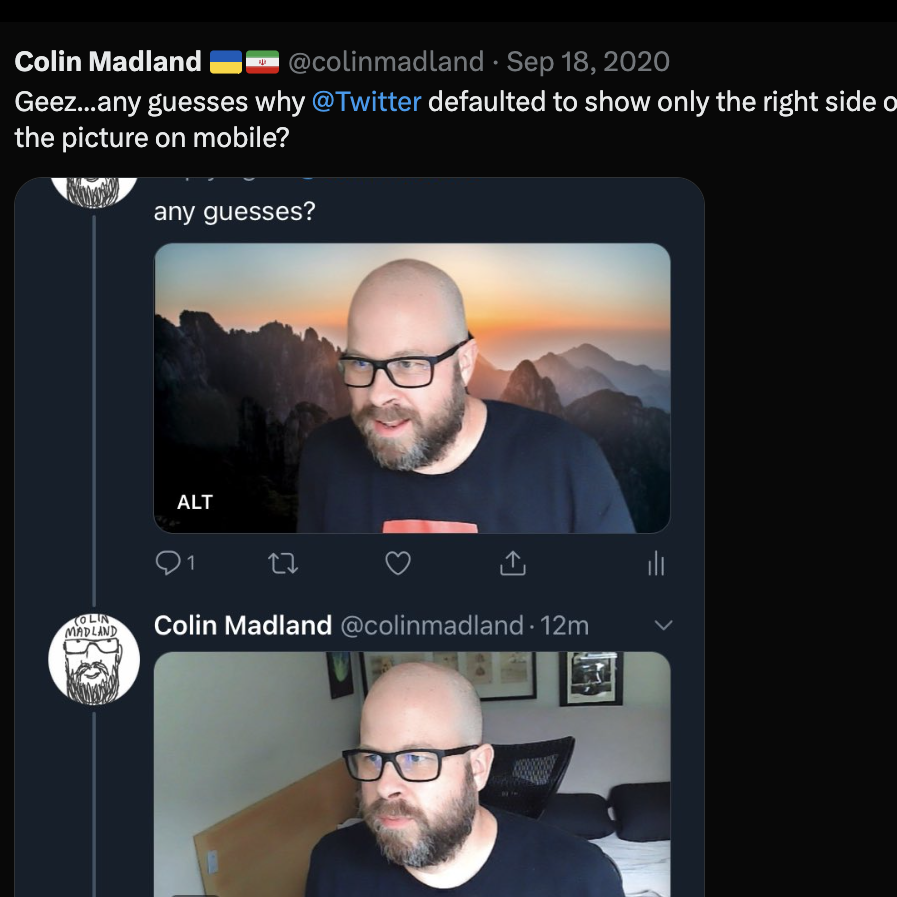
Todas as vezes que ele postou a imagem, a parte visível só exibia o seu lado da foto.
Depois de algumas tentativas, ele percebeu o viés do algoritmo que estava exibindo só o rosto branco.
O Twitter tem uma ferramenta de postagem de imagens que, usando IA, tenta recortar imagens que não cabem na moldura do post. O algoritmo tenta identificar características presentes na foto de forma a exibir um detalhe interessante ou atraente para os usuários.
Quando Colin chamou a atenção dos seus contatos para esse fato, outros muitos começaram a fazer diferentes testes usando imagens de pessoas brancas e não brancas em todas as combinações possíveis.



O resultado era sempre o mesmo, a imagem era alinhada para exibir o rosto branco.
O Twitter pediu desculpas e justificou dizendo que o algoritmo tinha passado por avaliações exaustivas mas evidentemente ainda precisava muito trabalho.
Entretanto o problema está menos no algoritmo quanto no treinamento, as pessoas que supervisionaram o processo de aprendizado da inteligência artificial viram esses resultados e consideraram corretos porque não conseguiram ver além dos seus vieses culturais.
Esse problema tem sua origem num meio profissional pouco diverso que serve como caixa de ressonância para ideias pre-concebidas que não são discutidas ou problematizadas antes de lançar produtos para o grande público, que acaba sendo a última fase do treinamento da IA, mas gerando grandes custos de imagem ou financeiros para a empresa e revolta de grupos que se vêm tratados com desrespeito e até invisibilizados.
Hoje o recurso de recorte da miniatura já não está disponível, as imagens são centralizadas por padrão e pronto, criando um recorte estranho mas inócuo para o Twitter.
Comments are closed