

Completitude é uma das dimensões de Qualidade de Dados. A completitude pode ser medida pela porcentagem de dados vazios ou nulos em uma tabela / dataframe.
Com Python Pandas, podemos criar de forma simples e rápida um sumário da Completitude da seguinte forma:
Criamos ou carregamos um dataframe:
meu_dataframe= pd.DataFrame(minha_tabela, columns=titulos)
Criamos uma variável para receber a soma das células vazias/na (Not Available) das séries multiplicada por 100 e dividida pelo número de células na série:
perc_na = meu_dataframe.isna ().sum() * 100 /len(meu_dataframe)
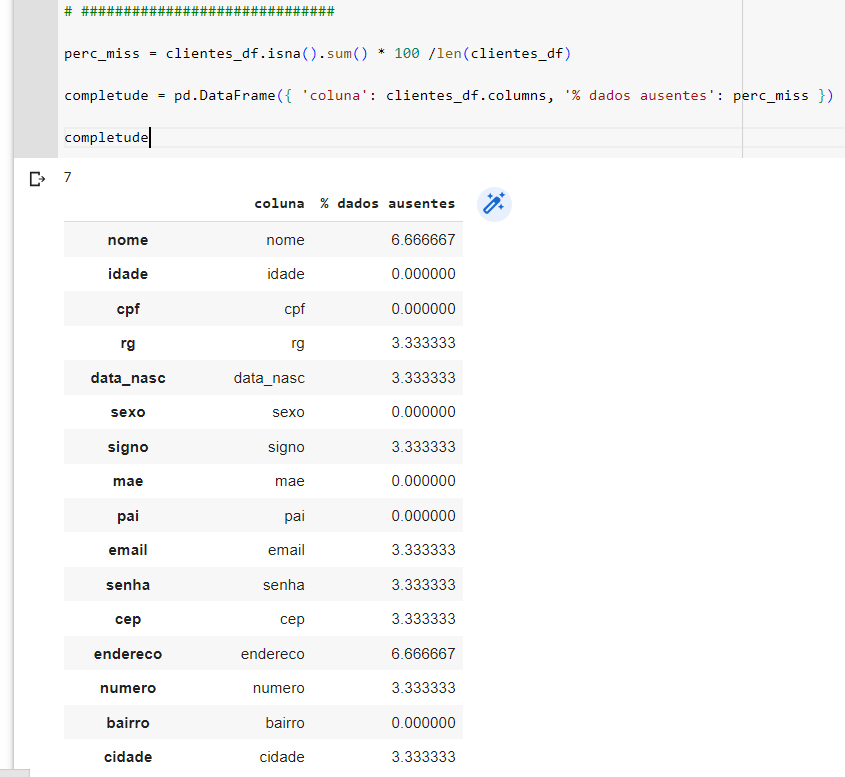
Agora criamos um novo dataframe para receber um dicionário com uma coluna com a lista de títulos das séries do dataframe original e outra com as percentagens de perc_na:
completude = pd.DataFrame( { 'coluna': clientes_df.columns, '% dados ausentes': perc_na } )
Resultado:
completude
Comments are closed