


Trabalhar com qualidade de dados se envolve monitorar as fontes de dados e detectar problemas anomalias.
Há fontes de dados entrando. Podem ser dados estruturados ou seus data lakes. Onde quer que se armazenem os dados importantes, é necessário analisá-los.
A plataforma deve analisar suas fontes de dados em busca de dois tipos de problemas de qualidade de dados:
Alterações nas fontes de dados
Executar testes mais aprofundados usando verificações de qualidade de dados ajustadas
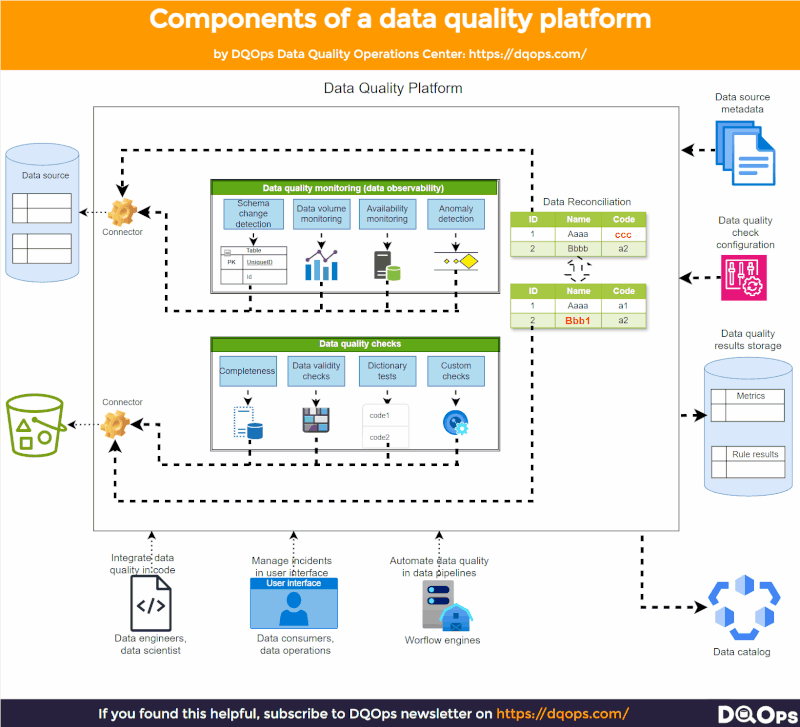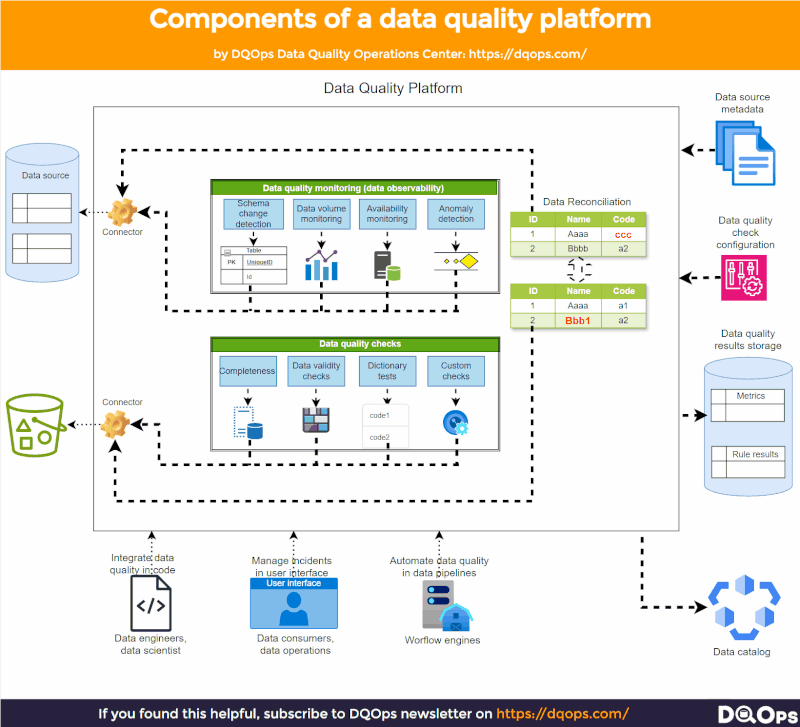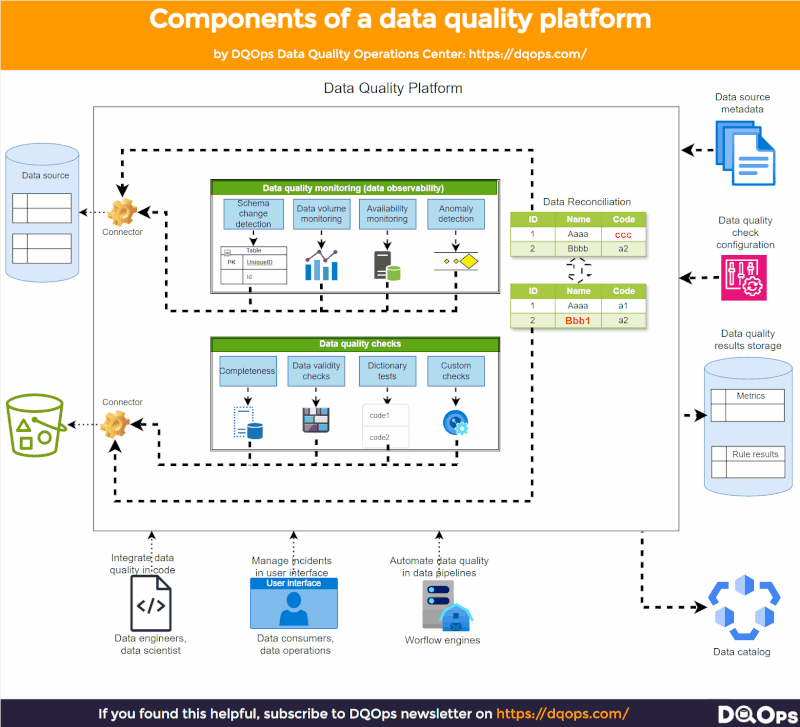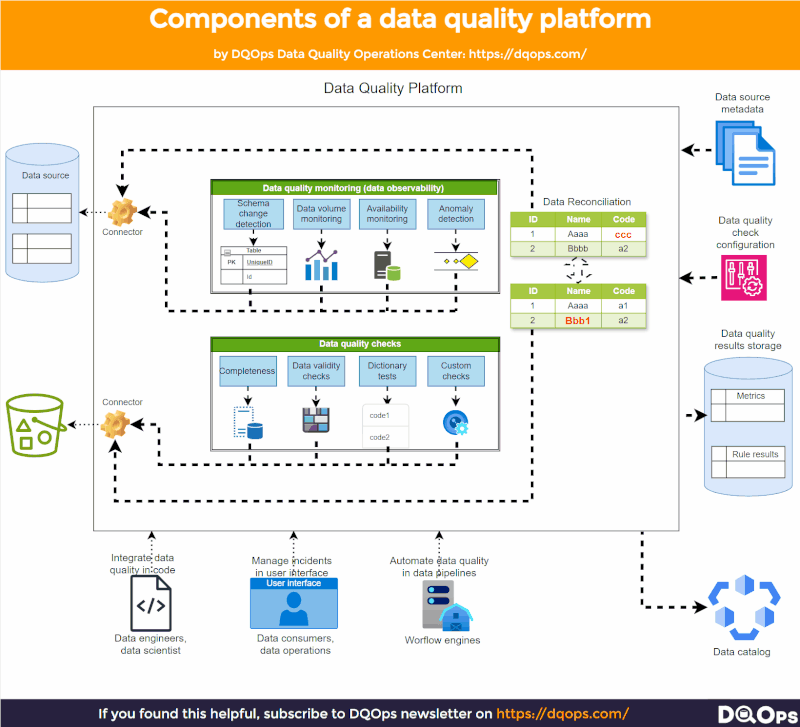
Monitorar as fontes de dados é simples e é chamado de observabilidade de dados.
A plataforma deve capturar métricas, armazená-las em algum lugar e compará-las na próxima vez que monitorar sua fonte de dados.
É possível detectar:
🔸 Mudanças no esquema da tabela
🔸 Atualização de dados
🔸 Mudanças de volume, como um aumento repentino no número de linhas
🔸 Anomalias nos dados
A qualidade real dos dados é o próximo passo. É aí que se configuram verificações extras de qualidade de dados com base nos requisitos de consumidores e usuários de dados.
As verificações completas da qualidade dos dados irão:
🔸 Validar padrões
🔸 Analisar a integridade dos dados de todos os ângulos
🔸 Detectar duplicatas em todo o conjunto de dados
🔸 Executar verificações personalizadas de qualidade de dados
Finalmente, é necessário armazenar isso em um banco de dados de resultados de qualidade de dados.
A plataforma também deve contar com interfaces funcionais para seus usuários, possibilitando a integração com as pipelines de dados. As necessidades dos usuários técnicos que preferem código são diferentes daquelas da equipe de operações de dados que eventualmente assumirá a manutenção da plataforma de dados.
É fundamental sincronizar os resultados da qualidade dos dados com um catálogo de dados. Alguém adorará ver como os ativos de dados são pontuados em termos de dimensões de qualidade de dados, como integridade, atualidade, validade e muitas outras.
Comments are closed